Overfitting and Underfitting in Machine Learning
Overfitting and Underfitting are two of the common issues that we face while training machine learning models. In this article, we will discuss overfitting and underfitting in machine learning. We will also discuss how to avoid overfitting and underfitting using various techniques.
Before we start with a discussion on overfitting and underfitting, I suggest you read this article on bias and variance in machine learning.
What is Overfitting in Machine Learning?
Overfitting is a phenomenon in which a machine-learning model accurately predicts the target value for all the data points in the training data but fails to give reliable output for unseen data points.
To understand overfitting, suppose that we have the following data points.
| x | y |
|---|---|
| 30 | 110 |
| 40 | 105 |
| 50 | 120 |
| 60 | 110 |
| 70 | 221 |
In this dataset, we have five values of x with 5 associated values of y. We need to train a machine learning model to predict the value y for any given x. If we try to train a machine learning model for this data set, the regression line for a trained but overfitted machine learning model will look as follows.
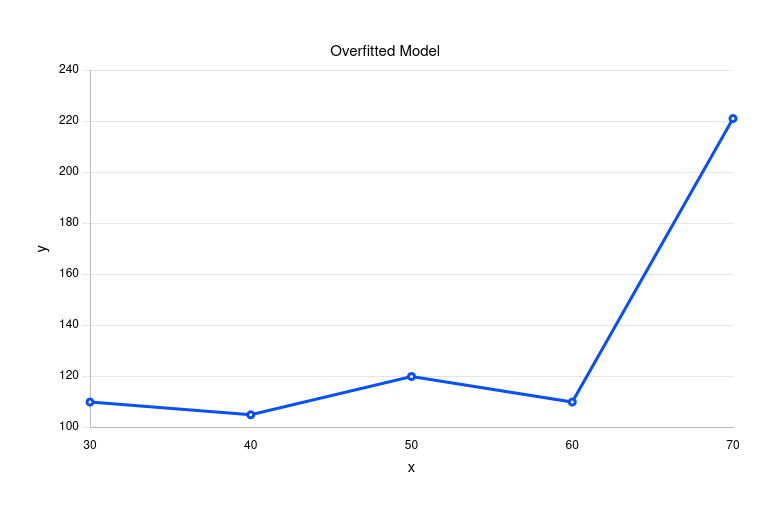
In the above image, you can observe that the regression line depicting the machine learning algorithm passes through all the input data points. Due to this, the model will have very very low bias and very high variance. It will not be able to predict accurate values of y for unseen x values.
You might say that the regression model that generates the above regression line will be efficient as it accurately predicts y for all the x values in training data. However, this isn’t our goal. Our goal for training a machine learning model is to create a generalized regression model that can predict the y values for training and new x values to a certain degree of accuracy. If we don’t get a generalized model, this purpose isn’t served.
From Overfitting to Underfitting in Machine Learning
For the dataset given in the previous example, if we start decreasing the number of parameters i.e. the degree of the regression function, we will start getting generalized models. For instance, the regression line for a regression function with degree value 3 will look like this.

In the above image, you can observe that the regression line is capturing the trends in the data by passing as close as possible to the training data points. Due to this, the regression model can generalize well and it can also accurately predict y values for unseen x. Hence, we can say that we have removed overfitting from the model.
Now, if we decrease the degree of the regression function to 2 in the model, the regression line will look as follows.
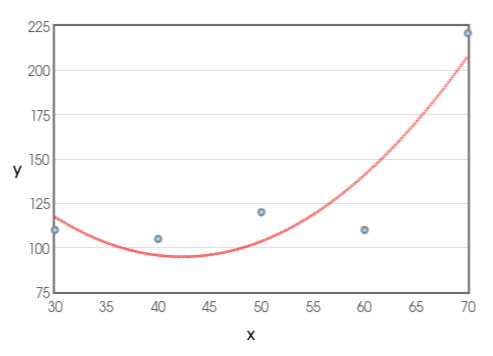
In the above image, we have set the degree of regression function to 2. Due to this, the number of model parameters decreases further. In the image, you can observe that the regression line isn’t passing by any of the input data points. However, it’s still capturing the general trend in the data. Thus, it possibly can predict y values for unseen x values with a certain accuracy.
Finally, if we decrease the degree of the regression function to 1, i.e. if we map the data points with a linear regression function, the regression line will look as follows.
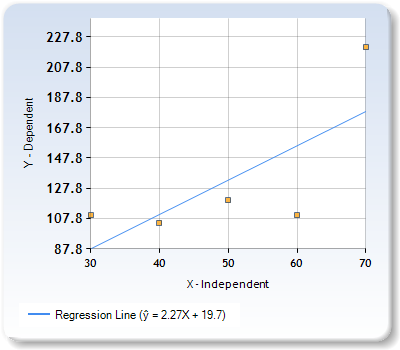
In the above image, you can observe that the regression line doesn’t even capture the trends of the input data points correctly. Due to this, the regression model will not perform well for training as well as unseen data points. This phenomenon is called underfitting. Thus, if we keep decreasing the parameters for the machine learning model while training, we move from overfitting to underfitting.
When underfitting occurs, the machine learning model has high bias and low variance. It will not be able to learn the trends in the training data. Consequently, it will reduce the accuracy of the predictions.
How to Avoid Overfitting and Underfitting?
Both overfitting and underfitting are bad for the machine learning models. Hence, we need to reduce overfitting and underfitting.
To reduce overfitting in a model, you can use the following techniques.
- Train with a large dataset: When we train machine learning models on smaller datasets, it is possible that the model will not generalize and will lead to overfitting. Hence, using a sufficient amount of training data can also help us avoid overfitting.
- Reduce the number of parameters: In the example images, you might have observed that when we decrease the degree of the regression function, the regression line is generalized more. This is due to the reason that number of parameters in the model decreases. Hence, if you decrease the number of parameters in the machine learning model, it will generalize more and you can avoid overfitting.
- Use ensemble learning methods: In ensemble learning, we use multiple machine learning models instead of training a single model. After training multiple models, we assign them weights to generate the final output. For ensemble learning, we use techniques like bagging, boosting, and random forests.
- Use regularization: Regularization is used to calibrate machine learning models in order to minimize the adjusted loss function and prevent overfitting or underfitting. We use regularization techniques like Lasso and Ridge regularization for this purpose.
- Use cross-validation: In cross-validation, we use different samples of data for training and testing in different iterations. Here, we first divide the dataset into multiple samples. Then, we take one of the samples of the data as a validation set and train the machine learning model with the rest of the data. After training, we evaluate the performance of the model using the validation data set. We repeat this process multiple times, each time using a different sample as the validation set. Finally, the results from each validation step are averaged to produce a more robust estimate of the model’s performance. This helps us avoid model overfitting and provides a realistic estimate of the model’s generalization.
To avoid underfitting the machine model, you can increase the number of features in the training data or the number of parameters in the model. In the examples shown above, you might have observed that when we move from linear functions to functions with higher degrees, the underfitting decreases.
In real-world applications, we need to select a model in between the overfitted or underfitted model. For instance, if we have to train a regression model with the data given in this article, the linear model causes underfitting whereas if we increase the degree of the regression function to 5, we get an overfitted model. However, for regression functions with degrees 2 and 3, we get pretty much-generalized regression lines. Hence, we can use any of these models by evaluating them on different parameters.
Conclusion
In this article, we discussed overfitting and underfitting in machine learning. To learn more about machine learning topics, you can read this article on KNN regression. You might also like this article on categorical data encoding techniques.
I hope you enjoyed reading this article. Stay tuned for more informative articles.
Happy Learning!